
ASSALAMMU'ALAIKUM WR. WB
Data mining merupakan 2 kata yang berasal dari kata "data" dan "mining". Data merupakan sekumpulan informasi, fakta, serta pengetahuan bersifat real atau fakta. Sedangkan mining berarti memperoleh atau mengelola data yang telah dicari dan diproses menjadi pengetahuan. Data mining memiliki banyak sekali metode-metodenya adapun diantaranya klasifikasi, klastering, asosiasi, dan beberapa lainnya.
Contoh kecil penggunaan data mining dalam kehidupan perkuliahan adalah mendata kelas bagi mahasiswa. Dimana akan diperlukan nim dan nama dan akan digunakan untuk pengurutan absen dikelas tersebut.
Komponen Nilai | Nilai |
|---|---|
Tugas/Quiz | 30% |
30% | |
30% | |
Presensi | 10% |
PERTEMUAN 1 - PENGANTAR
ASSALAMMU'ALAIKUM WR. WB
Apa kabar teman-teman semua? Semoga teman-teman diberi kesehatan selalu ya.. Pada pertemuan ke 1 ini kita akan membahas pengantar data mining.
Pada abad ke-21 ini data sudah terbuat dan/atau terkumpul dari berbagai sumber. Data terbuat terus dari detik ke detik dalam 24 jam dalam sehari. Pada tahun 2020 ini, diprediksi dihasilkan sekitar 35 zettabytes (10 bytes atau 1.000.000.000.000.000.000.000 bytes) dari seluruh dunia (IBM Cognitive Class-2, 2020). Fenomena ini menyebabkan "Ledakan Data", akan tetapi banyak yang tidak menyadari dari data-data tersebut kita dapat menggali informasi / memanfaatkan potensi dari suatu data, kita kaya akan data tetapi miskin informasi.
Data Mining merupakan Disiplin ilmu yang mempelajari metode untuk mengekstrak pengetahuan atau menemukan pola dari suatu data yang besar. Dengan contoh kasus yang dibahas pada pertemuan kali ini akan memberikan gambaran kepada teman-teman bagaimana data mining dapat memberikan kita informasi yang berguna sehingga dapat menjadi pendukung pengambilan keputusan.
Modul Pengantar Data Mining : Modul Pengantar Data Mining
Tugas Pertemuan 1 : Download
PERTEMUAN 2 - PERAN UTAMA DATA MINING
ASSALAMMU'ALAIKUM WR. WB
Hai teman-teman, kita bertemu kembali di pertemuan ke 2. Kali ini kita akan membahas tentang :
- Data untuk data mining
- Peran utama data mining
- Metode data mining
- Preprocessing data CRISP–DM
Tetap semangat mengikuti perkuliahan ya teman-teman
Modul Peran Utama Data Mining : Modul Peran Utama Data Mining
Tugas Pertemuan 2 : Download
PERTEMUAN 3 - PROCESSING DATA

Assalammu'alaikum wr. wb.
Hai teman-teman, kita bertemu kembali di pertemuan ke 3 yaa.. kali ini kita akan membahas Preprocessing Data. Preprocessing data sangat penting karena kesalahan, redundan, missing value, dan data yang tidak konsisten menyebabkan berkurangnya akurasi hasil analisis. Jadi, sebelum mengolah data, kita harus memastikan bahwa data yang akan kita gunakan merupakan data "bersih".
PERTEMUAN 4 - METODE LEARNING
Assalammu'alaikum wr. wb.
Tugas data mining sebenarnya adalah analisis otomatis atau semi-otomatis jumlah besar data untuk mengekstrak pola yang menarik yang sebelumnya tidak diketahui seperti kelompok catatan data (analisis cluster), catatan yang tidak biasa (deteksi anomali) dan dependensi (aturan asosiasi pertambangan).
Hal ini biasanya melibatkan menggunakan teknik database seperti indeks spasial. Pola ini kemudian dapat dilihat sebagai semacam ringkasan dari input data, dan dapat digunakan dalam analisis lebih lanjut atau, misalnya, dalam pembelajaran mesin dan analisis prediktif. Misalnya, langkah data mining mungkin mengidentifikasi beberapa kelompok dalam data.
Dalam pertemuan ke 4 ini kita akan membahas beberapa metode yang diterapkan dalam data mining.
Modul Metode Learning : Download
PERTEMUAN 5 - NAIV BAYES

Assalammu'alaikum wr. wb.
PERTEMUAN 6 - K-Nearest Neighbor (KNN)

ASSALAMMU'ALAIKUM WR. WB.
Salah satu algoritma yang dapat digunakan untuk metode learning Klasifikasi adalah K - Nearest Neighbor (KNN). KNN merupakan pendekatan untuk mencari kasus lama, yaitu berdasarkan pada pencocokan bobot dari sejumlah fitur yang ada.
Salah satu contoh KNN adalah untuk mencari solusi terhadap pasien baru dengan menggunakan solusi dari pasien terdahulu dengan menghitung kedekatan kasus pasien baru dengan semua kasus pasien lama. Kasus pasien lama dengan kedekatan terbesarlah yang akan diambil solusinya untuk digunakan pada kasus pasien baru.
Yuk kita sama-sama pelajari bagaimana algoritma KNN bekerja. Pada pertemuan kali ini akan dibagi menjadi 2 sesi, yaitu :
1. Sesi Materi
Merupakan sesi untuk membahas perhitungan manual dari suatu kasus dengan menggunakan algoritma KNN.
2. Sesi Praktikum
Merupakan sesi untuk membahas penggunaan tools pada Python untuk contoh kasus algoritma KNN dengan menggunakan Google Colabs. Teman - teman dapat mendownload dataset Social Network Ads. csv yang sudah tersedia pada LMS yang akan kita gunakan dalam sesi praktikum.
Video Praktikum
Tugas pertemuan 6 : Download
PERTEMUAN 7 - Decision Tree

ASSALAMMU'ALAIKUM WR. WB
Alhamdulillah kita kita masih diberi kesempatan untuk bertemu pada pertemuan ke 7. Masih semangat ya teman-teman..
Pada pertemuan kali ini kita akan membahas tentang algoritma C4.5. Algoritma C4.5 merupakan algoritma yang digunakan untuk membentuk pohon keputusan (Decision Tree). Pohon keputusan merupakan metode klasifikasi dan prediksi yang terkenal. Pohon keputusan berguna untuk mengekspolari data, menemukan hubungan tersembunyi antara sejumlah calon variable input dengan sebuah variable target.
Salah satu contoh penggunaan algoritma C4.5 adalah membuat pohon keputusan untuk menentukan main tenis atau tidak dengan melihat keadaan cuaca, temperatur, kelembaban dan keadaan angin.
Pertemuan ini dibagi menjadi 2 sesi, yaitu :
1. Sesi Materi
Merupakan sesi untuk membahas perhitungan manual dari suatu kasus dengan menggunakan algoritma Decision Tree C.45
2. Sesi Praktikum
Merupakan sesi untuk membahas penggunaan tools pada Python untuk contoh kasus algoritma Decision Tree C.45 dengan menggunakan Google Colabs. Teman - teman dapat mendownload dataset Dataset Iris.csv yang sudah tersedia pada LMS yang akan kita gunakan dalam sesi praktikum.
Modul decision Tree : Download
Tugas topik 7 : Download


Algoritma Clustering adalah meletakkan nilai yang serupa dalam satu segmen, dan meletakkan nilai yang berbeda dalam cluster yang berbeda (Wu & Kumar, 2009). Algoritma K-Means diterapkan pada objek yang diwakili dalam bentuk titik didalam ruangan vector berdimensi-d. K-Means mengcluster semua data didalam setiap dimensi dimana titik dalam segmentasi yang sama diberi cluster ID. Nilai dari K adalah masukan dasar dari algoritma yang menentukan jumlah segmentasi yang ingin dibentuk. Partisi akan dibentuk dari sekumpulan objek n kedalam cluster k sehingga terbentuk kesamaan objek dalam setiap segmentasi k.
Pertemuan ini dibagi menjadi 2 sesi, yaitu :
1. Sesi Materi
Merupakan sesi untuk membahas perhitungan manual dari suatu kasus dengan menggunakan algoritma K - Means.
Rekaman Clustering dengan K-Means
2. Sesi Praktikum
Merupakan sesi untuk membahas penggunaan tools pada Python untuk contoh kasus algoritma K - Means dengan menggunakan Google Colabs. Pada sesi praktikum ini kita menggunakan dataset bawaan dari phyton yaitu dataset iris.csv.

Hierarchical Clustering adalah metode analisis kelompok yang berusaha untuk membangun sebuah hirarki kelompok data. Strategi pengelompokannya umumnya ada 2 jenis yaitu Agglomerative (Bottom-Up) dan Devisive (Top-Down). Pada bagian ini hanya akan dibatasi menggunakan konsep Agglomerative (Bottom-Up). Pada pertemuan kali ini kita akan membahas tentang
Agglomerative Hierarchical Clustering .
Pertemuan ini dibagi menjadi 2 sesi, yaitu :
1. Sesi Materi
Merupakan sesi untuk membahas perhitungan manual dari suatu kasus dengan menggunakan algoritma AHC.
2. Sesi Praktikum
Merupakan sesi untuk membahas penggunaan tools pada Python untuk contoh kasus algoritma AHC dengan menggunakan Google Colabs. Teman - teman dapat mendownload dataset AHC.xlsx yang sudah tersedia pada LMS yang akan kita gunakan dalam sesi praktikum.
ASSALAMMU'ALAIKUM WR. WB
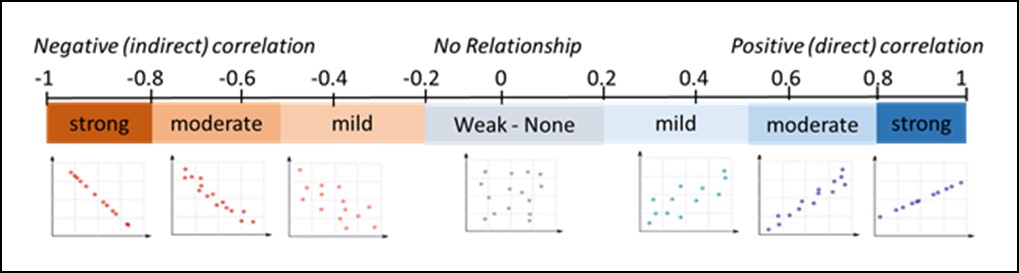
Regresi dapat digunakan untuk memprediksi nilai dari variable terikat apabila terdapat kenaikan atau penurunan pada variable bebas. Pada regresi terdapat istilah korelasi yang digunakan untuk mengukur hubungan antara dua variable. Metode dalam regresi adalah regresi linear berganda, metode ini dapat kita gunakan salah satunya untuk memprediksi pengeluaran rumah tangga dalam seminggu berdasarkan variabel pendapatan dalam seminggu dan variabel jumlah anggota rumah tangga.
Pertemuan ini dibagi menjadi 2 sesi, yaitu :
1. Sesi Materi
Merupakan sesi untuk membahas perhitungan manual dari suatu kasus dengan menggunakan algoritma Regresi Linear Berganda.
2. Sesi Praktikum
Merupakan sesi untuk membahas penggunaan tools pada Python untuk contoh kasus algoritma regresi dengan menggunakan Google Colabs. Teman - teman dapat mendownload dataset Data Penjualan.xlsx yang sudah tersedia pada LMS yang akan kita gunakan dalam sesi praktikum.
ASSALAMMU'ALAIKUM WR. WB
Pertemuan ini dibagi menjadi 2 sesi, yaitu :
1. Sesi Materi
2. Sesi Praktikum
Merupakan sesi untuk membahas penggunaan tools pada Python untuk contoh kasus algoritma regresi dengan menggunakan Google Colabs. Teman - teman dapat mendownload dataset Online_Retail.xlsx yang sudah tersedia pada LMS yang akan kita gunakan dalam sesi praktikum.
Assalammu'alaikum wr. wb
Artificial Neural Network (ANN) merupakan temuan penting dalam bidang Machine Learning. ANN terinspirasi oleh sistem saraf otak manusia (neuron) dalam melakukan klasifikasi data. Namun, pemodelan syaraf buatan pada ANN jauh lebih sederhana dibandingkan dengan neuron yang sebenarnya. Terdapat banyak model ANN yang telah diusulkan, baik belajar secara supervised ataupun unsupervised. Pertemuan ini dibagi menjadi 2 sesi, yaitu :
1. Sesi Materi
Merupakan sesi untuk membahas materi tentang Artificial Neural Network (ANN).
2. Sesi Praktikum
Merupakan sesi untuk membahas penggunaan tools pada Python untuk contoh kasus ANN dengan Multi Layer Perceptron untuk klasifikasi diabetes dengan menggunakan Google Colabs. Teman - teman dapat mendownload dataset diabetes_uji.csv dan diabetes_latih.csv yang sudah tersedia pada LMS yang akan kita gunakan dalam sesi praktikum.
** Lembar kerja Google Colab studi kasus Klasifikasi Diabetes **
https://colab.research.google.com/drive/10U3RYVhru8RQLSUKZ5SIq5ife5GDMV65#scrollTo=RcxwK8hxmBlK
Modul ANN : Download
Diabetes_uji.csv : Download
Diabetes_latih.csv : Download
Kuis ANN : Download
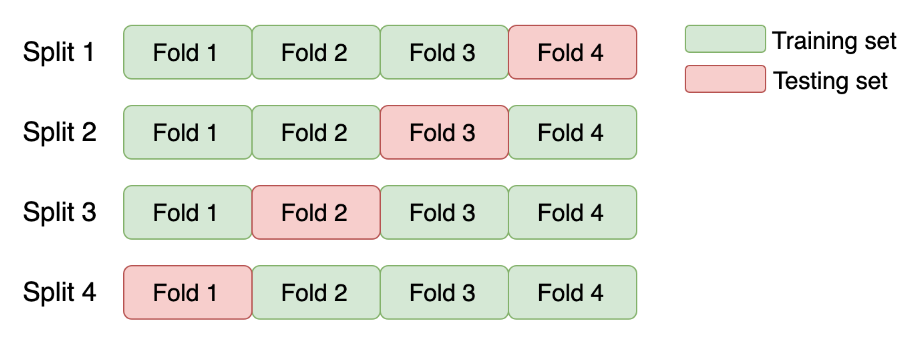
PERTEMUAN 15 - VALIDASI DAN PENGUJIAN MODEL
ASSALAMMU'ALAIKUM WR. WB
Modul : Download
Kuis : Download
PERTEMUAN 16 - UAS
Soal UAS : Download
ujian cpmk belum ya?
BalasHapus